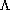 (C) for the
(C) for the
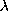 -calculus
with a particular constant set C.
-calculus
with a particular constant set C.
For this work, we'll write (C) for the
-calculus
with a particular constant set C.
So far, we've looked at the -calculus as a formalism which we can
manipulate according to rules that do (I hope) seem reasonable. Now, we
could take the -calculus itself as a basis for computation -
it's fairly easy to implement what we've defined as a computational
structure, particularly using a LISP derivative (Scheme, POP-11, SML...).
However, from a computational point of view, to restrict ourselves to a
literal implementation of 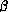 -reduction as a means of
computation is problematic, because substitution as defined involves
extensive copying of structures if it is implemented in the most obvious
way. So, it's desirable to think of ways that we can map the
-calculus onto various kinds of structure some of which will be more
efficient computationally.
-reduction as a means of
computation is problematic, because substitution as defined involves
extensive copying of structures if it is implemented in the most obvious
way. So, it's desirable to think of ways that we can map the
-calculus onto various kinds of structure some of which will be more
efficient computationally.
Mathematically, there is also a problem with the unvarnished -calculus. Since we are interested in using it a basis for
specifying computations that we can prove correct. Unfortunately
the -calculus, as we currently know it, is paradoxical
when used as the basis for a logic. So, we'd like to see how we can
eliminate the possibility of paradox, by restricting ourselves to forms
which are seen as legal.
To illustrate this problem, let's adapt an example from Meyer[1982]. Consider the term
f x. f(f x)
z. z3) 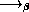 x. (( z. z3) (( z. z3) x))
x. (( z. z3) (( z. z3) x))
 x. (( z. z3) x3)
x. (( z. z3) x3)
x. (x3)3
x. x9
Now, consider the term (T T). Can we
can put an interpretation upon it, despite the fact that it would not be
legal if we think of -expressions as being mathematical
functions, because in the standard mathematical concept of functions,
a function can't lie in its own domain. But if (T T) is
legal, and T is seen as a mathematical function, then T
must lie in its own domain, a contradiction.
Nevertheless, there is a commonsense interpretation that can bu put upon (T T). Consider the expression:
f x. f(f x)) T) g
(( x. T(T x)) ) g
T(T g)
T(( f x. f(f x)) g)
T( x. g(g x) )
( f x. f(f x))( x. g(g x) )
( x.
( x. g(g x) )
(( x. g(g x) )
x)))
( x.
( x. g(g x) ) ( g(g x) ))
( x. (g (g (g (g x)))))
(g x. (g (g (g (g x)))))
T o T
However allowing self-application, as in (T T), can lead to contradiction. For example, suppose we define a (higher-order) function P by the rule
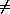 0
0
(P f) = 1 otherwise
Note that if we regard the above "definition" of P as being instead an equation for P, the paradox disappears, just as the equation x + 1 = x is not paradoxical, merely insoluble.
Now there is a long tradition in mathematics of characterising functions by equations. The elementary trancendental functions sin, cos.. can be characterised by differential equations, and indeed more advanced functions, such as the Bessel functions are primarily characterised by differential equations.
Similarly, we can regard recursive functions, such as the factorial function, as solutions of recursion equations. Thus if we solve
n. (if (= n 0) 1 (* n (f (- n 1))))
n. f (- n 1)
Bearing in mind the above discussion, from both the computational and
mathematical point of view, it's useful to proceed abstractly by focussing
on the idea of mapping the -calculus to some
kind of domain in which computation takes place. By considering
what should be the essential properties of such a map we can hope
to characterise a useful variety of domains.
Such abstraction is second-nature to mathematicians raised in the modern
tradition; computer scientists can reflect that what we are trying to do is
to characterise an abstract data type which will allow us to
consider a range of possible implementations of the -calculus.
Perhaps the simplest possible mathematical representation of an abstract concept of computation is focus on the idea of the application of a program-object to a data-object. If we want to be faithful to the functional paradigm (and indeed to the idea of the von Neumann architecture), we will require that program-objects and data-objects inhabit the same applicative algebra.
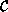 = <D,
= <D,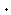 >
on which is defined a
binary operation, called application.
For any f, x
>
on which is defined a
binary operation, called application.
For any f, x  D, we write the application of
f to x as
x
D, we write the application of
f to x as
xWe will write D = | |.
Now our concept of applicative algebra seems rather austere. There is no
apparent apparatus, for example, for defining functions. The one thing we
don't want to do is to re-introduce the -apparatus directly into the
algebra, since that would prohibit us investigating other means of
realising its capabilities. Instead, let's consider a map from the
-calculus to our applicative algebra. Such a map, which
we'll call an evaluation, is going to be built up from a simple
map from the variables and constants,C, of (C)
to . Such a map is commonly called an environment.
So, the idea is, given an environment which tells us what
are the values in of variables and constants of
(C), how can we define an evaluation which maps the
whole of (C) to . Such an evaluation ought to
preserve certain properties of the -calculus, so that we can feel
that the -calculus is faithfully represented in .
Since we don't want explicitly to reproduce the -apparatus in
, we can proceed indirectly to develop our concept of
faithfulness by requiring that -calculus terms which are
alpha- and beta- equivalent be mapped onto identical members of .

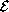
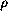 (x) = (x)
(c)
= (c)
((E1 E2))
= (E1)
(E2)
( x.E) =
(
y.E[x:=y])
when y is not free in E
(( x.E) F) =
(E[x:=F])
(C) can be mapped directly into operations on an
applicative algebra. But EV4 and EV5 are less directly helpful -
EV4 merely relates two abstractions, which is not a manifest
construct of an applicative algebra, while EV5 relates abstraction to
substitution, which is again something we don't know how to do.
(x) = (x)
(c)
= (c)
((E1 E2))
= (E1)
(E2)
( x.E) =
(
y.E[x:=y])
when y is not free in E
(( x.E) F) =
(E[x:=F])
(C) can be mapped directly into operations on an
applicative algebra. But EV4 and EV5 are less directly helpful -
EV4 merely relates two abstractions, which is not a manifest
construct of an applicative algebra, while EV5 relates abstraction to
substitution, which is again something we don't know how to do.
Rescue from our predicament arrives in the the form of our old friends the S and K combinators.
y x . y
S = f g x . (f x) (g x)
Now suppose we have an evaluation that, for some , maps
(C)
onto . Let
d1,d2,d3 . Let
D1, D2, D3 be
the inverse-images of d1,d2,d3
under
Consider the expression
(K) d1 d2
= (K) (D1) (D2)
= (K D1 D2) = (D1) = d1
(S)
d1 d2 d3
(S) (D1) (D2) (D3)
= (S D1 D2 D3) = ((D1 D3) (D2 D3))
= (d1 d3) (d2 d3)
Thus any applicative domain that is the image of
(C) under an evaluation contains analogs of the
S and K
combinators. This turns out, as we shall see, to be an important aspect of
what it is to be a domain which is a model of the (C)
calculus.
is said to be a combinatory
algebra if there are elements
K, S ||
such that
K d1 d2
= d1
CA2
S d1 d2 d3
= (d1 d3) (d2 d3)
(from Meyer[1982], originally from Curry.)
One way in which we can extend an environment into being an evaluation is to make use of the S and K elements of a combinatory algebra. To do this, we will need an additional element I, in effect the identity function, which is shown necessarily to exist by the following lemma.
be a combinatory algebra. Let I = SKK then
for all d D
|, we have
I d = S K K d = (K d) (K d) = d
(C), every term is 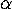 --equivalent to a term in which the only
-abstractions are the S, K, I combinators. If we
do this, it will then be fairly obvious how we can create an evaluation
mapping to a combinatory algebra.
--equivalent to a term in which the only
-abstractions are the S, K, I combinators. If we
do this, it will then be fairly obvious how we can create an evaluation
mapping to a combinatory algebra.
CT1
If v (C) is a variable then
v is a combinatory lambda term.
CT2
If c C is a constant then c is a combinatory
lambda term.
CT3
If F,G are combinatory lambda terms, then so is (F G)
CT4
S,K are combinatory lambda terms (and hence so is I).
(C) to an equivalent combinatory term.
To do this, we introduce a piece of notation that I found rather baffling
when first I saw it. In essence, the notation <x> E means
"the combinatory lambda equivalent of x . E".
We could, of course, have used some more conventional notation
such as comb(x,E) in defining the transformation to combinatory
terms, but the syntactic similarity of <x> E to the form plays a useful role in helping us to understand what
is happening.
(C) then, for any
combinatory lambda term
E (C), the term denoted by
<x> E is defined as follows:
CL1
<x> x = I
CL2
<x> E = (K E) if x is not free in E
CL3
<x>(F G) = (S (<x>F) (<x>G))
if x is free in F or G.
Now we can define the transformation from a term E to
an equivalent combinatory term by specifying that we systematically replace
any abstraction v. F occurring in E
by <v> F
(C). Then
comb(E) of E is defined by
CM1
comb(c) = c for c C
CM2
comb(x) = x for any variable x
CM3
comb((F G)) = (comb(F) comb(G))
CM4
comb( x. F) = <x>comb(F)
(C)
then
comb(E) is a combinatory lambda term.
E comb(E)
where denotes - equivalence.
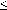 n we have that
comb(E) is a combinatory lambda term
and E comb(E).
n we have that
comb(E) is a combinatory lambda term
and E comb(E).
Consider a term E for which height(E) = n+1
and so by the inductive hypothesis and CT3, comb((F G)) is a
combinatory lambda term. Moreover, by the definition of - equivalence, since we have, from the
inductive hypothesis, comb(F) F,
comb(G) G, that
(F G)
x. F.
Here, by CM4
x. F) = <x>comb(F)
Now by the inductive hypothesis, comb(F) is a combinatory lambda term equivalent to F.
( x. x)
E
x. F)
= (K comb(F))
( u v. u) comb(F)
( v. comb(F))
applying the definition of K and equivalence.
So, by the inductive hypothesis, and -conversion
this is
( x. F)
since x is not free in comb(F)
x. F)
= <x> comb((G H))
= <x> (comb(G) comb(H))
= (S (<x> comb(G)) (<x> comb(H)))
= (S comb( x. G)
comb( x. H))
(( f g x. (f x) (g x))
comb( x. G)
comb( x. H))
(( f g x. (f x) (g x))
( x. G)
( x. H))
( x. G[x:=x] H[x:=x])
= ( x. G H)
= E
x . ((+ x) 1)
As a reality check, if we transform back any one line by replacing the <x>.. form by the corresponding lambda abstraction, we should obtain a function equivalent to the initial one. Consider
x . + x)) ( x . 1))
f g z. (f z) (g z))
( x . + x)) ( x . 1))
z. (( x . + x) z)
(( x . 1) z))
z. (+ z) 1)
CL3
<x>(F G) = (S (<x>F) (<x>G))
if x is free in F or G.
Using S in this case in effect is piping x into both the transformed versions of F and G. This only makes sense if x is free in both. So, let's introduce two new combinators, defined as follows
B = f g x. f (g x)
C = f g x. (f x) g
CL3'
<x>(F G) = (S (<x>F) (<x>G))
if x is free in F and G.
CL4
<x>(F G) = (B F (<x>G))
if x is only free in G.
CL5
<x>(F G) = (C (<x>F) G)
if x is only free in F.
x . ((+ x) 1)
-abstractions give rise to expressions that grow
too rapidly. [Peyton-Jones has a good discussion on this - see section
16.2]
Consider an expression of the form F G. A single
lambda-abstraction translates, in the most general case,
( z. F G) into
y z. F G) into
x y z. F G) into
= S(B S (B (B S) (<x><y><z>F))) (<x><y><z>G))
<x>((B E) F) = (B (B E) <x>F)That is, every abstraction replaces each such occurrence B combinator by 2 occurrences of a B. So we'd seem to have an exponential dependence on the number of abstractions.
We can remedy this problem by introducing yet another family of combinators, the Turner combinators (have faith - we're not going to do this indefinitely). The most important of these is S', and its definition is:
h f g x. h (f x) (g x)
CL2.9
<x>(H F G) = (S' H (<x>F) (<x>G))
if x is not free in H
but is free in F or
G.
Reverting to our consideration of abstraction over
an expression of the form F G, we see that a single
lambda-abstraction translates, as before,
( z. F G) into
y z. F G) into
x y z. F G) into
= (S' (S' S) (<x><y><z>F) (<x><y><z>G))
Peyton Jones discusses the use of the B' and C' combinators, which bear the same relation to S' as S' does to S. He points out that the use of B' is not necessarily beneficial, and discusses an alternative B* combinator.
The following lemma shows that it's correct to use these new combinators and their rules in the comb function.
(C)
and comb is defined using rules CL1,CL2,CL2.9,CL3',CL4,CL5, then
comb(E) is a combinatory lambda term.
E comb(E)
where denotes - equivalence.
n we have that
comb(E) is a combinatory lambda term
and E comb(E).
Consider a term E for which height(E) = n+1
and so by the inductive hypothesis and CT3, comb((F G)) is a
combinatory lambda term. Moreover, by the definition of - equivalence, since we have, from the
inductive hypothesis, comb(F) F,
comb(G) G, that
(F G)
x. F.
Here, by CM4
x. F) = <x>comb(F)
Now by the inductive hypothesis, comb(F) is a combinatory lambda term equivalent to F.
( x. x)
E
x. F)
= (K comb(F))
( u v. u) comb(F)
( v. comb(F))
applying the definition of K and equivalence.
So, by the inductive hypothesis, and -conversion
this is
( x. F)
since x is not free in comb(F)
x. F)
= <x> comb((J G H))
= <x> (comb(J) comb(G) comb(H))
= (S' comb(J) (<x> comb(G)) (<x> comb(H)))
= (S' comb(J) comb( x. G)
comb( x. H))
(( j f g x. j (f x) (g x))
comb(J)
comb( x. G)
comb( x. H))
(( j f g x. j (f x) (g x))
J
( x. G)
( x. H))
( x. J G[x:=x] H[x:=x])
= ( x. J G H)
= E
x. F)
= <x> comb((G H))
= <x> (comb(G) comb(H))
= (S (<x> comb(G)) (<x> comb(H)))
= (S comb( x. G)
comb( x. H))
(( f g x. (f x) (g x))
comb( x. G)
comb( x. H))
(( f g x. (f x) (g x))
( x. G)
( x. H))
( x. G[x:=x] H[x:=x])
= ( x. G H)
= E
x. F)
= <x> comb((G H))
= <x> (comb(G) comb(H))
= (B comb(G) (<x> comb(H)))
= (B comb(G)
comb( x. H))
(( f g x. f (g x))
comb(G)
comb( x. H))
(( f g x. f (g x))
G
( x. H))
( x. G H[x:=x])
= ( x. G H)
= E
The first combinatory term lemma provides one approach to constructing
an evaluation of an arbitrary term E of (C). All we need to do is to transform E into an
equivalent combinatory term E', which can then be mapped into an
arbitrary combinatory algebra using rules EV1-EV3.
The second combinatory term lemma suggests a more efficient approach
in which we use the additional combinators B,C,S' to obtain
relatively condensed combinatory terms. Since the new combinators can be
defined in terms of S and K, we can again map a combinatory
term E'' obtained from E by use of the second lemma, into
using rules EV1-EV3.
Computationally, of course, it would be important to implement the new combinators as part of any implementation of a combinatory algebra - mathematically however they're already there.
Mathematically, however, there is a snag. While we've shown that the
concept of evaluation requires that an applicative algebra must be
a combinatory algebra if it is the image of (C) under
evaluation, and we've shown one way to construct a mapping from
(C) to a combinatory algebra, we haven't shown that
the mapping so constructed is an evaluation. In fact, we need a
stronger concept than the combinatory algebra.
This situation will be familiar to computer scientists. An abstract data-type may be characterised by some kind of type-signature which partly specifies what the functions acting on the data-type should do, and what kinds of objects the data-type should have. But a program that meets the type-signature is not necessarily a correct implementation of the data-type. Even the equations we have put upon combinatory algebras, in CA1 and CA2, are too weak.
There are two approaches to remedying this problem. The algebraic approach is to add additional conditions beyond CA1 and CA2 which will characterise a structure called a Lambda Algebra. The non-algebraic approach is to add non-algebraic conditions beyond CA1 and CA2 which will characterise a structure called a Combinatory Model. D. A. Turner ``Another Algorithm for Bracket Abstraction'', Journal of Symbolic Logic, vol 44, no 2, pp 267-270 (June 1979).